Visualizing Crime Incident Reports in Boston
In this episode of "Ankit tries to convince his flatmate that neighbourhoods in Boston are safer than they are made out to be.", we'll look at some of the data that we've collected about crime incidents in Boston.




Introduction
Moving to a new city in the US is a big deal. The rent is high. It often makes financial sense to move in with more people. This also means that one has to be considerate of other people's preferences and opinions when looking for apartments. At 9pm on a Monday, my flatmate informed me that he was having trouble convincing another flatmate that a certain neighbourhood in Boston was safe or at least as safe as where we currently live. This sounded like a nice Toy Problem to me. Something that I could use Data Visualization to help me with. After all, I had taken CS6250. I wasn't going to let Prof. Michelle Borkin down.
This exploration did not start with me looking for other implementations to place my work against but as an innocent exploration of the medium that is code and data. As I worked on the project, I also looked up if others had attempted to set sail on a similar voyage and of course, people had, many of them. A few of the projects are highlighted below.
-
This blogpost by Riley Huang was a wonderful read. Riley does a brilliant job of using a dataset that they are passionate about and coming up with a story and designing a learning plan around it. I'm glad I found this blogpost before I posted this one. Riley uses Python and Pandas.
-
This blogpost by Brian Ford of Wentworth Institute of Technology is another great read. Brian uses the data to make a web application using the Google Maps API. Brian uses Web Technologies to make the application.
-
This blogpost by Namas Bhandari is a short jupyter notebook that performs a brief exploration of the data.
-
This tableau dashboard by Amulya Aankul of Northeastern University is another great read. Amulya uses the data to make an effective tableau dashboard with slides to guide the reader through. Amulya also attempts to infer causal factors that could affect crime. Amulya uses datasets in addition to the Boston Crime dataset to build a narrative.
Over the course of the project, I decided to also explore ways to grouping the data as we will see soon.
Collecting the Data
The City of Boston as part of the Open Data Project publishes civic data on the Analyze Boston website. We are interested in Crime Incident Reports.
The data for each year from 2015 is available as a separate csv file. There are two additional .xlsx files for the offense codes and the different field descriptions. Let us begin by scraping the download links off of the website. The download links are parents to the <i> tags that have the class icon-download.
Let's begin by importing the necessary libraries. Click on show to see the imports.
# importing libraries
# for web scraping
from bs4 import BeautifulSoup
import requests as r
# for data wrangling
import pandas as pd
from pandas import DateOffset
import json
import uuid
import datetime
import numpy as np
from tslearn.barycenters import dtw_barycenter_averaging
from tslearn.clustering import TimeSeriesKMeans
from minisom import MiniSom
# for plotting
import networkx as nx
import matplotlib.pyplot as plt
import seaborn as sns
from PIL import Image
import io
import pydot
import matplotlib.colors as mcolors
import random
import math
import matplotlib.dates as mdates
# for map plotting
import folium
from folium.plugins import HeatMap, FastMarkerCluster, HeatMapWithTime
from IPython.display import IFrame, display, Markdown, Latex, SVG, HTML
import branca.colormap
from IPython.display import Image as imgIpython
# misc
from tqdm import tqdm
import os
from collections import defaultdict
We begin by getting the html source for the page. This can be achived using a simple GET request to the URL.
url = "https://data.boston.gov/dataset/crime-incident-reports-august-2015-to-date-source-new-system"
res = r.get(url)
Next we use the BeautifulSoup library to parse the html source. Using the parsed output we select the csv and xlsx download links and download them.
soup = BeautifulSoup(res.text, "html.parser")
downloadBtns = soup.find_all('i', {"class": "icon-download"})
urls = [ btn.parent['href'] for btn in downloadBtns ]
csvLinks = [ url for url in urls if url.endswith('.csv') ]
xlLinks = [ url for url in urls if url.endswith('.xlsx') ]
from tqdm import tqdm
dfs = []
os.makedirs("./data", exist_ok=True)
for link in tqdm(csvLinks):
# downloading using requests
# and writing to a file
res = r.get(link)
with open("./data/" + link.split('/')[-1],'w') as f:
f.write(res.text)
df = pd.read_csv("./data/" + link.split('/')[-1], low_memory=False)
dfs.append(df)
xl_dfs = []
for link in tqdm(xlLinks):
# downloading using requests
# and writing to a file
res = r.get(link)
with open("./data/" + link.split('/')[-1],'wb') as f:
f.write(res.content)
df_xl = pd.read_excel("./data/" + link.split('/')[-1])
xl_dfs.append(df)
combined = pd.concat(dfs)
combined.to_csv("./data/combined.csv")
Let's take a look at the datatypes of the columns.
combined.dtypes
Let's fix the data types for the columns and also fill in NA values. The Offense codes are four digit codes. We will use the zfill function to fill in the missing digits with 0s.
combined_typed = combined.astype(
{
"INCIDENT_NUMBER": "str",
"OFFENSE_CODE": "str",
"OFFENSE_CODE_GROUP": "str",
"OFFENSE_DESCRIPTION": "str",
"DISTRICT": "str",
"REPORTING_AREA": "str",
"SHOOTING": "bool",
"OCCURRED_ON_DATE": "datetime64",
"DAY_OF_WEEK": "str",
"UCR_PART": "str",
"STREET": "str",
"Location": "str",
}
)
combined_typed.fillna("", inplace=True)
combined_typed["OFFENSE_CODE"] = combined_typed["OFFENSE_CODE"].map(lambda x: x.zfill(4))
# drop duplicates
combined_typed.drop_duplicates(inplace=True)
combined_typed.to_csv("./data/combined_typed.csv",index=False)
combined_typed.head()
Let's look at the number of reports per year.
year_counts_df = pd.DataFrame(
[[k,v] for k,v in combined_typed.groupby(['YEAR'])['YEAR'].count().to_dict().items()],
columns=['YEAR', 'COUNT']
)
year_counts_df
Oh right we can plot the values and take a look at them visually too.
ax = year_counts_df.plot(kind='bar', x='YEAR', y='COUNT')
ax.set_title("Number of Reports Per Year")
ax.set_xlabel("Year")
ax.set_ylabel("Number of Reports")
ax.legend().remove()

Let's now take a look at the number of reports per offense code for the entire dataset.
sns.set_context("notebook")
offense_plot = combined_typed['OFFENSE_CODE'].value_counts().plot(kind='bar',figsize=(40,6))
offense_plot.set_title("Number of Reports Per Offense Code")
offense_plot.set_xlabel("Offense Code")
offense_plot.set_ylabel("Number of Reports")
offense_plot.legend().remove()

Ok That's a lot of Offense Codes. Making sense of this plot will need a really large monitor given how skewed the aspect ratio is. Let's first try to take a look at the 25 most common offense codes, their descriptions and their code groups to get a feel for the data.
top25_codes = combined_typed[['OFFENSE_CODE','OFFENSE_DESCRIPTION','OFFENSE_CODE_GROUP']]\
.value_counts()\
.head(25)\
.reset_index(name='COUNTS')
top25_codes
Let us also take a look at the top 5 most common offense codes for each year.
df2015 = combined_typed[(combined_typed['YEAR'] == 2015)]
top5_codes_2015 = df2015[['OFFENSE_CODE','OFFENSE_DESCRIPTION']].value_counts().head(5).reset_index(name='COUNTS')
display(Markdown('**Top 5 Codes in 2015:**'))
top5_codes_2015
df2016 = combined_typed[(combined_typed['YEAR'] == 2016)]
top5_codes_2016 = df2016[['OFFENSE_CODE','OFFENSE_DESCRIPTION']].value_counts().head(5).reset_index(name='COUNTS')
display(Markdown("**Top 5 Codes in 2016:**"))
top5_codes_2016
df2017 = combined_typed[(combined_typed['YEAR'] == 2017)]
top5_codes_2017 = df2017[['OFFENSE_CODE','OFFENSE_DESCRIPTION']].value_counts().head(5).reset_index(name='COUNTS')
display(Markdown("**Top 5 Codes in 2017:**"))
top5_codes_2017
df2018 = combined_typed[(combined_typed['YEAR'] == 2018)]
top5_codes_2018 = df2018[['OFFENSE_CODE','OFFENSE_DESCRIPTION']].value_counts().head(5).reset_index(name='COUNTS')
display(Markdown("**Top 5 Codes in 2018:**"))
top5_codes_2018
df2019 = combined_typed[(combined_typed['YEAR'] == 2019)]
top5_codes_2019 = df2019[['OFFENSE_CODE','OFFENSE_DESCRIPTION']].value_counts().head(5).reset_index(name='COUNTS')
display(Markdown("**Top 5 Codes in 2019:**"))
top5_codes_2019
df2020 = combined_typed[(combined_typed['YEAR'] == 2020)]
top5_codes_2020 = df2020[['OFFENSE_CODE','OFFENSE_DESCRIPTION']].value_counts().head(5).reset_index(name='COUNTS')
display(Markdown("**Top 5 Codes in 2020:**"))
top5_codes_2020
df2021 = combined_typed[(combined_typed['YEAR'] == 2021)]
top5_codes_2021 = df2021[['OFFENSE_CODE','OFFENSE_DESCRIPTION']].value_counts().head(5).reset_index(name='COUNTS')
display(Markdown("**Top 5 Codes in 2021:**"))
top5_codes_2021
df2022 = combined_typed[(combined_typed['YEAR'] == 2022)]
top5_codes_2022 = df2022[['OFFENSE_CODE','OFFENSE_DESCRIPTION']].value_counts().head(5).reset_index(name='COUNTS')
display(Markdown("**Top 5 Codes in 2022:**"))
top5_codes_2022
Let's now take a look at a heatmap of the numbers of reports for the year 2021. We'll be using folium for map visualization. Let us also add markers that correspond to the agregated counts for a geographic region.
hmap = folium.Map(location=[42.336082675630315, -71.09991318861809], zoom_start=15,tiles='OpenStreetMap', )
data = list(zip(df2021.Lat.values, df2021.Long.values))
steps=20
colormap = branca.colormap.linear.YlOrRd_09.scale(0, 1).to_step(steps)
gradient_map=defaultdict(dict)
for i in range(steps):
gradient_map[1/steps*i] = colormap.rgb_hex_str(1/steps*i)
colormap.add_to(hmap)
hm_wide = HeatMap( data,
min_opacity=0.2,
radius=17, blur=15,
max_zoom=1,
gradient=gradient_map,
name='heatmap'
)
hmap.add_child(hm_wide)
markers = FastMarkerCluster(data=data,name='markers')
hmap.add_child(markers)
folium.LayerControl().add_to(hmap)
hmap.save("../images/heatmap.html")
IFrame("/images/heatmap.html", width="100%", height="500px")
Keep in mind that this is the aggredgated-count heatmap for all incident types for 2021. To see the heatmap for a specific year we can change the line data = list(zip(df2021.Lat.values, df2021.Long.values)) to our desired year. In order to see the heatmap for a sepecific indident type we can add a filter to the dframe. For example, to see the heatmap for all crimes involving the offense code 3115 we can add a filter to the dataframe like so: df2021[df2021.OFFENSE_CODE == '3115'].
We can also take a look at a heatmap over time. For this we will use the folium plugin HeatMapWithTime. The data we need to past is a list of lists of locations. The index for the data will be our bins of time.
combined_typed["OCCURRED_ON_DATE"] = pd.to_datetime(combined_typed["OCCURRED_ON_DATE"])
c_indexed = combined_typed.set_index('OCCURRED_ON_DATE')
c_indexed_grouped = c_indexed.groupby(['OCCURRED_ON_DATE'])
Let's also define a helper function to convert a latitude and longitude string of the form (42.3601, -71.0589) to a tuple of floats.
def convert_lat_long(lat_long_str):
lat_long_str = lat_long_str.replace('(','')
lat_long_str = lat_long_str.replace(')','')
lat_long_str = lat_long_str.split(',')
lat = float(lat_long_str[0])
long = float(lat_long_str[1])
return [lat,long]
Let's resample the data to get the number of reports per Month and create a list of lists of locations for each month.
sampled = c_indexed.resample("M")
locations = sampled.agg(pd.Series.tolist)["Location"]
data = [ [ convert_lat_long(point) for point in timeframe] for timeframe in locations]
# remove points that are undefined and (0,0)
data = [point for point in data if point[0] != 0 and point[1] != 0]
data = [point for point in data if point[0] is not None and point[1] is not None]
All together now.
hmap = folium.Map(location=[42.336082675630315, -71.09991318861809], zoom_start=15,tiles='OpenStreetMap', )
steps=20
colormap = branca.colormap.linear.YlOrRd_09.scale(0, 1).to_step(steps)
gradient_map=defaultdict(dict)
for i in range(steps):
gradient_map[1/steps*i] = colormap.rgb_hex_str(1/steps*i)
colormap.add_to(hmap)
hm_wide = HeatMapWithTime( data,
min_opacity=0.2,
radius=17,
max_opacity=0.8,
gradient=json.dumps(gradient_map),
)
hmap.add_child(hm_wide)
hmap.save("../images/heatmap_time.html")
IFrame("/images/heatmap_time.html", width="100%", height="500px")
It is obvious that maps are excellent for visualizing geographical data. Their limits as a visual aid are put to the test when we have multiple data class types like in the case of incident reports. Naively we could visualize different classes with different colors. We 254 different classes. Using all of them would make the visualization immpossible to interpret. Using the viz principle of Details on Demand, another strategy would be to use brushing and linking to bind a set of selections from a less granualar visualization like a bar chart or a dropdown list (a table) to a map.
The humble line chart is never one to disappoint. On that note, let us take a look at the number of counts per month for the time range as a time series line chart.
ax = c_indexed.resample("M").count()["INCIDENT_NUMBER"].plot(figsize=(30,10))
ax.set_title("Number of Reports Per Month")
ax.set_xlabel("Month")
ax.set_ylabel("Number of Reports")
display(Markdown("### Total Reports per Month"))
ax.legend().remove()

We can get a more fine grained view of the data by taking a look at the number of counts per week for the time range.
# resample weekly
ax = c_indexed.resample("W").count()["INCIDENT_NUMBER"].plot(figsize=(30,10))
ax.set_title("Number of Reports Per Week")
ax.set_xlabel("Week")
ax.set_ylabel("Number of Reports")
display(Markdown("### Total Reports per Week"))
ax.legend().remove()

The data appears to be seasonal in nature. Lets take a look at a specific Incident Code.
# select rows matching a specific offense code and resample weekly
offense_code = '0613'
time_scale = "W"
ax = c_indexed[c_indexed["OFFENSE_CODE"] == offense_code].resample(time_scale).count()["INCIDENT_NUMBER"].plot(figsize=(30,10))
description = combined_typed[combined_typed["OFFENSE_CODE"] == offense_code]["OFFENSE_DESCRIPTION"].iloc[0]
ax.set_xlabel(f"Year, data grouped by {time_scale}")
ax.set_ylabel("Number of Reports")
ax.set_title(f"Number of Reports for Offense {offense_code} Per {time_scale}")
display(Markdown(f"### Reports for Code {offense_code} ({description}) Grouped by Week"))
ax.legend().remove()

Larceny seems to have a dip in the first half of 2020. The overall trend appears to be stable.
# select rows matching a specific offense code and resample weekly
offense_code = '1831'
time_scale = "W"
ax = c_indexed[c_indexed["OFFENSE_CODE"] == offense_code].resample(time_scale).count()["INCIDENT_NUMBER"].plot(figsize=(30,10))
description = combined_typed[combined_typed["OFFENSE_CODE"] == offense_code]["OFFENSE_DESCRIPTION"].iloc[0]
ax.set_xlabel(f"Year, data grouped by {time_scale}")
ax.set_ylabel("Number of Reports")
ax.set_title(f"Number of Reports for Offense {offense_code} Per {time_scale}")
display(Markdown(f"### Reports for Code {offense_code} ({description}) Grouped by Week"))
ax.legend().remove()

Interestingly the number of sick assists have shot up in 2022. One can hypothesise that this is a filing error. The empty space between the end of 2019 and 2022 is likely due to the fact that COVID-19 induced filing delays.
# select rows matching a specific offense description and resample weekly
ax = c_indexed[c_indexed["OFFENSE_DESCRIPTION"] == 'VERBAL DISPUTE'].resample("W").count()["INCIDENT_NUMBER"].plot(figsize=(30,10))
ax.set_xlabel("Year, grouped by Week")
ax.set_ylabel("Number of Reports")
ax.set_title("Number of Reports for VERBAL DISPUTE Per Week")
display(Markdown("### Investigate Verbal Dispute Reports Grouped by Week"))
ax.legend().remove()

The onset of the pandemic also seems to correlate with a drop in the number of verbal disputes. Masks seem to have worked ![]() !
!
# select rows matching a specific offense description and resample weekly
ax = c_indexed[c_indexed["OFFENSE_DESCRIPTION"] == 'INVESTIGATE PERSON'].resample("W").count()["INCIDENT_NUMBER"].plot(figsize=(30,10))
ax.set_xlabel("Year, grouped by Week")
ax.set_ylabel("Number of Reports")
ax.set_title("Number of Reports for INVESTIGATE PERSON Per Week")
display(Markdown("### Investigate Person Reports Grouped by Week"))
ax.legend().remove()

This looks interesting. There's some interesting end of the year peaking happening in the number of Investigate Person reports. There could be so many factors at play here. These demands futher inquiry.
# select rows that have Shooting set to true and resample daily
ax = c_indexed[c_indexed["SHOOTING"] == True].resample("D").count()["INCIDENT_NUMBER"].plot(figsize=(30,10))
ax.set_xlabel("Year, grouped by Day")
ax.set_ylabel("Number of Shooting Reports")
ax.set_title("Number of Reports with shootings Per Day")
display(Markdown("### Shootings Grouped by Day"))
ax.legend().remove()

Oh my! What everyone was waiting for. Shootings dropped after 2019? This is weird. Did they change the filing code? or Did shootings drop because of change in adminisitration?
That's a drastic dip in the number of shootings after 2019. Unfortunately I am not well equipped to answer why this is the case. Looking into it will be a future project.
A first method is based on prefix codes. The Incident codes are in what appears to be prefix code. Prefix codes are codes where items sharing a common prefix share a parent.
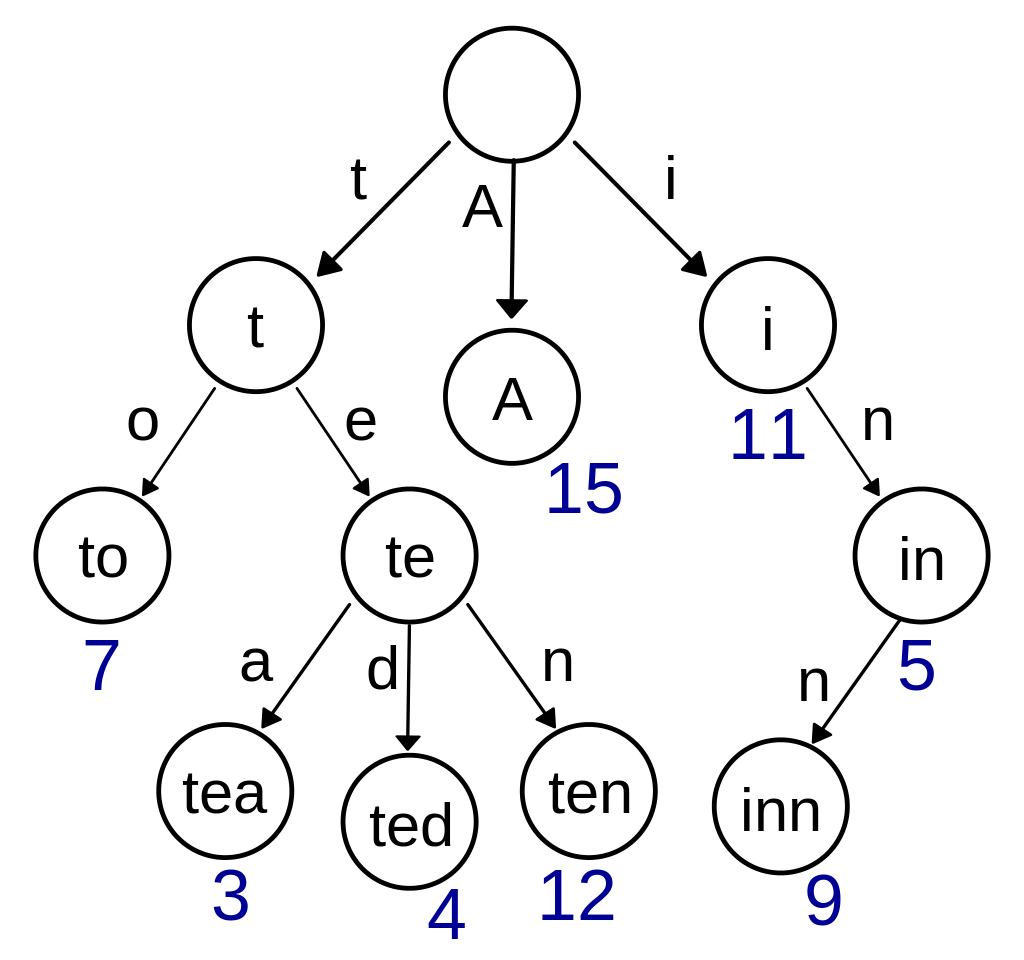
Let's build the prefix code tree of the offense codes. We begin by defining a recursive function to build the prefix code tree. The function process takes in a list of codes and returns a dictionary of prefixes and their corresponding children. The process is applied to each child node till we reach the leaf nodes.
def process(items,n=0):
if type(items) == list:
groups = {}
for item in items:
s = str(item)
if n >= len(s):
return items[0]
if s[n] in groups:
groups[s[n]].append(item)
else:
groups[s[n]] = [item]
for group in groups:
groups[group] = process(groups[group],n+1)
return groups
elif type(items) == dict:
return {k:process(v,n+1) for k,v in items.items()}
codeList = list(c_indexed["OFFENSE_CODE"].unique())
# remove code 99999
codeList.remove("99999")
We add a key s to the dictionary as a root node.
tree = {'s' : process(codeList)}
As a result we can now query the dictionary for codes that begin with 10 as follows,
tree['s']['1']['0']
As you can see each dictionary key is a prefix and the associated value is either the resulting code or a dictionary of prefixes and their children.
Let us rename the nodes by appending a unique code to each key. Since we have many repeating prefix keys it is possible that making a network of nodes will result in an incorrect vizualization since vertex names are unique in most graph/network processing packages like pydot and networkx.
sns.reset_orig()
sns.set_style("white")
rename_dict = {}
def alter_keys(dictionary, func):
empty = {}
for k, v in dictionary.items():
n = func(k)
if isinstance(v, dict):
empty[n] = alter_keys(v, func)
else:
empty[n] = v
return empty
def append_id(name):
new_name = name + "_" + str(uuid.uuid4())
rename_dict[name] = new_name
return new_name
renamed_tree = alter_keys(tree, append_id)
We now define a second recursive function that takes as input the renamed prefix tree and adds the edges to networkx digraph. We create an empty graph and the function addEdgeT adds edges to our empty graph.
G = nx.DiGraph()
def visit(node, parent=None):
for k,v in node.items():
if isinstance(v, dict):
# We start with the root node whose parent is None
# we don't want to graph the None node
if parent:
addEdgeT(parent, k)
visit(v, k)
else:
addEdgeT(parent, k)
# drawing the label using a distinct name
addEdgeT(k, k+'_'+str(v))
def addEdgeT(parent_name, child_name):
G.add_edge(parent_name, child_name)
visit(renamed_tree)
We can now check if the graph is planar and if it is a tree.
print(f" Is it planar ? : {nx.check_planarity(G)[0]}")
print(f" Is it a tree ? : {nx.is_tree(G)}")
Let's take a look at the network of prefixes.
nx.draw(G,node_size=2)

This hairball is not a canonical visualization of a tree. Let's use a different layout. A more pleasing visualization of a tree is a radial tree.

This is available to us as part of networkx which includes sections of the pydot library and some graphviz layout algorithms. We are interested in the twopi layout of a tree. We drive the edge colors based on the prefix code of the leaf nodes. Optionally we drive the edge labels using the prefix code of node. We next drive the size of the vertices and the edge width based on the icident counts for each prefix code.
Here I use arebitray functions to map the values to edge widths and vertex sizes. If n is the number of incidents for a prefix code, The edge widths are mapped to math.log(n,200) and the vertex sizes are mapped to (n/1000)*5.
fig, ax = plt.subplots(figsize=(12,12))
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
# pos = nx.planar_layout(G)
pos = nx.nx_pydot.graphviz_layout(gg, prog="twopi")
c_x,c_y = pos[rename_dict['s']]
# vertex colors
colors = list(mcolors.TABLEAU_COLORS.keys())
used_colors = []
vertex_colors = []
vertex_color_dict = {}
# color vertex if it is of type int white if it is not
for v in gg.nodes:
if type(v) == int:
first_digits = str(v).zfill(4)[0:1]
if first_digits not in vertex_color_dict:
vertex_color_dict[first_digits] = random.choice(list(set(colors) - set(used_colors)))
used_colors.append(vertex_color_dict[first_digits])
vertex_colors.append(vertex_color_dict[first_digits])
else:
vertex_colors.append(vertex_color_dict[first_digits])
else:
vertex_colors.append('black')
# edge colors
edge_colors = [ vertex_color_dict[str(v).zfill(4)[0:1]] if isinstance(v,int) else 'grey' for u,v in gg.edges]
# edge labels
edge_labels = {}
for e in gg.edges:
if type(e[1]) == int:
edge_labels[(e[0],e[1])] = str(e[1]).zfill(4)
else:
edge_labels[(e[0],e[1])] = e[1].split('_')[0]
# vertex size
counts = {}
vertex_size = []
for v in tqdm(gg.nodes):
if type(v) == int:
code = str(v).zfill(4)
# count the number of incidents with this code
n = c_indexed[c_indexed["OFFENSE_CODE"] == code].count()["INCIDENT_NUMBER"]
counts[v] = n
# log scale
vertex_size.append((n/1000)*5)
else:
vertex_size.append(0.01)
# edge width
edge_width = [math.log(counts[v],200) if isinstance(v,int) else 0.2 for u,v in gg.edges]
nx.draw_networkx_edges(gg,pos,ax=ax,edge_color=edge_colors,width=edge_width,arrows=False)
nx.draw_networkx_nodes(gg,pos=pos,node_size=vertex_size,node_color=vertex_colors,ax=ax)
#nx.draw_networkx_labels(gg,labels=labb,pos=pos,font_size=5,ax=ax,font_color='white')
nx.draw_networkx_edge_labels(gg,pos,edge_labels=edge_labels,ax=ax,font_size=3.5,font_color='black',label_pos=0.4)
buf = io.BytesIO()
fig.savefig('plots/categories_twopi_lab_color.svg')
ax.set_title('Categories',fontsize=20)
fig.savefig(buf)
buf.seek(0)
plt.close(fig)
im = Image.open(buf)
im.save('plots/categories_twopi_lab_color.png')
# save pos as json
with open('plots/pos_twopi_color.json', 'w') as fp:
json.dump(pos, fp)
Let's take a look at the resulting vizualization.
style = "<style>svg{width:100% !important;height:100% !important;</style>"
display(HTML(style))
SVG('plots/categories_twopi_lab_color.svg')
Here, each color is associated with codes that share the same prefix at a particular position. For example 0001 and 0000 share the same parent node corresponding to the prefix 000. The scales are arbitrary and thus need trial and error to make them work with the visualization. As you can see the circles are impossible to see for some incidents. Some incident counts are just too low to be visible. An alternative visualization could use the normalized incident counts to drive the size of the circles.
Time for some animations. Let us make the plot move with time. This visualization is by no means a replacement for the humble line plot but an aid to help the user demand the right plots to later visualize. We begin by sorting the dataframe by its index. Here the index is the column OCCURRED_ON_DATE.
We can now group by the OFFENSE_CODE column and count the number of occurrences per rolling window. We can use these counts to drive the plot and generate frames of the animation. Let us take a look at slice of the output.
c_indexed
df = pd.crosstab(combined_typed["OCCURRED_ON_DATE"].dt.to_period('2W'), combined_typed['OFFENSE_CODE'])
df
We can now build a list of count dictionaries for each time period. We can then use these dictionaries to drive the plot using the same code.
i_s = df.index.to_series().values.tolist()
count_list = []
for ix,i in tqdm(enumerate(i_s)):
counts = {}
d = df.iloc[ix,:].to_dict()
for v in gg.nodes:
if type(v) == int:
code = str(v).zfill(4)
counts[v] = d[code]
count_list.append(counts)
frames = []
for counts in tqdm(count_list):
vertex_size = []
for v in gg.nodes:
if type(v) == int:
code = str(v).zfill(4)
n = counts[v]
vertex_size.append(n)
else:
vertex_size.append(0.01)
fig, ax = plt.subplots(figsize=(12,12))
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
# pos = nx.planar_layout(G)
pos = nx.nx_pydot.graphviz_layout(gg, prog="twopi")
c_x,c_y = pos[rename_dict['s']]
edge_colors = [ vertex_color_dict[str(v).zfill(4)[0:1]] if isinstance(v,int) else 'grey' for u,v in gg.edges]
edge_width = [math.log(max(0.1,counts[v]),200) if isinstance(v,int) else 0.2 for u,v in gg.edges]
nx.draw_networkx_edges(gg,pos,ax=ax,edge_color=edge_colors,width=edge_width,arrows=False)
nx.draw_networkx_nodes(gg,pos=pos,node_size=vertex_size,node_color=vertex_colors,ax=ax)
#nx.draw_networkx_labels(gg,labels=labb,pos=pos,font_size=5,ax=ax,font_color='white')
nx.draw_networkx_edge_labels(gg,pos,edge_labels=edge_labels,ax=ax,font_size=3.5,font_color='black',label_pos=0.4)
buf = io.BytesIO()
fig.savefig('plots/categories_twopi_lab_color.svg')
fig.savefig(buf)
buf.seek(0)
plt.close(fig)
im = Image.open(buf)
frames.append(im)
gif_name = 'plots/categories_twopi_lab_color.gif'
frames[0].save(gif_name, format='GIF', append_images=frames[1:], save_all=True, duration=100, loop=0)
Adding a timestamp to the plot should help us understand the plot better. We will use PIL to add the timestamp to the plot since generating the matplotlib frames again is a computationally expensive operation.
from PIL import ImageDraw
new_frames = []
for i,frame in enumerate(frames):
im = frames[i].copy()
# add frame to image
draw = ImageDraw.Draw(im)
draw.text((130,130), str(i_s[i]), fill=(0,0,0))
new_frames.append(im)
gif_name = 'plots/categories_twopi_lab_color.gif'
new_frames[0].save(gif_name, format='GIF', append_images=new_frames[1:], save_all=True, duration=100, loop=0)
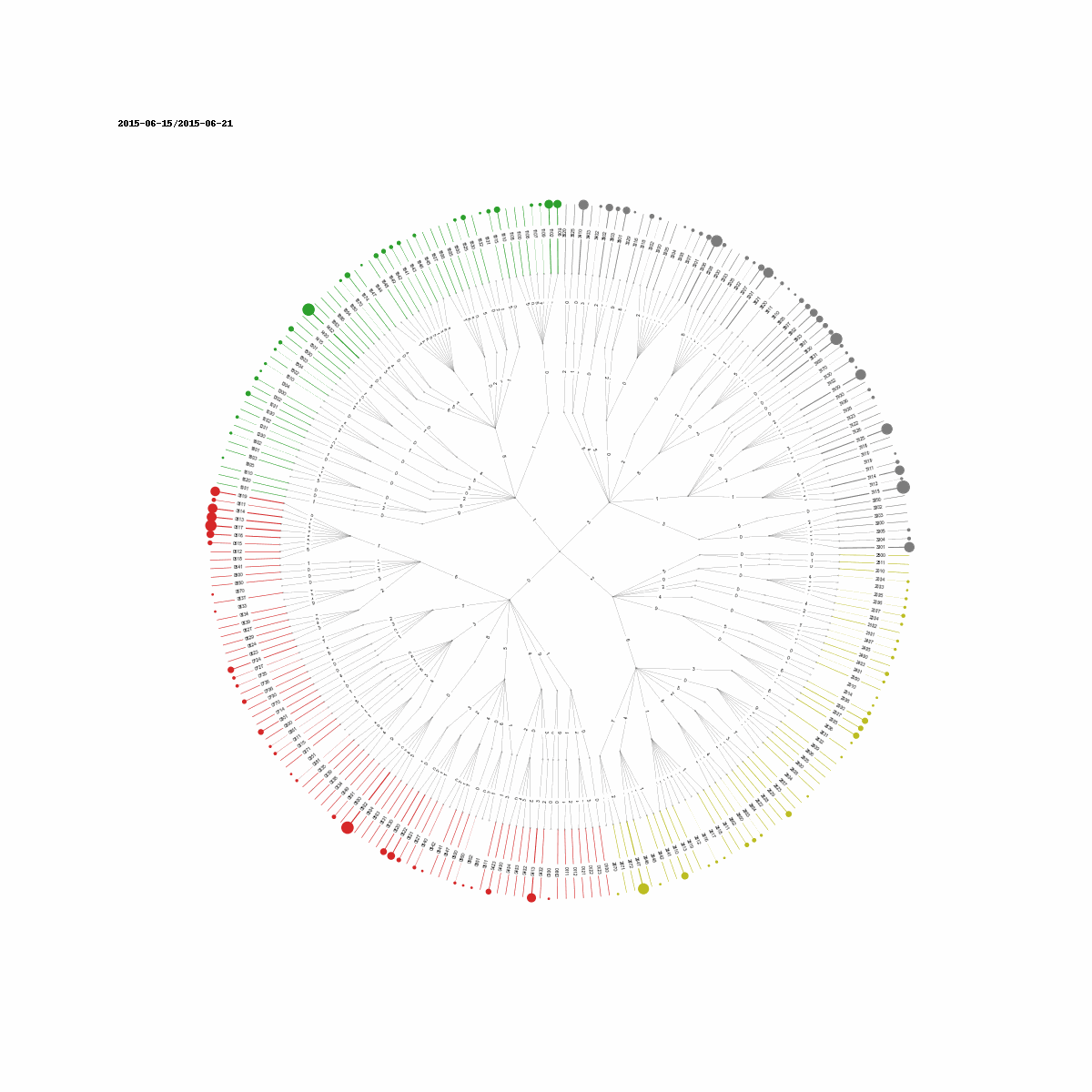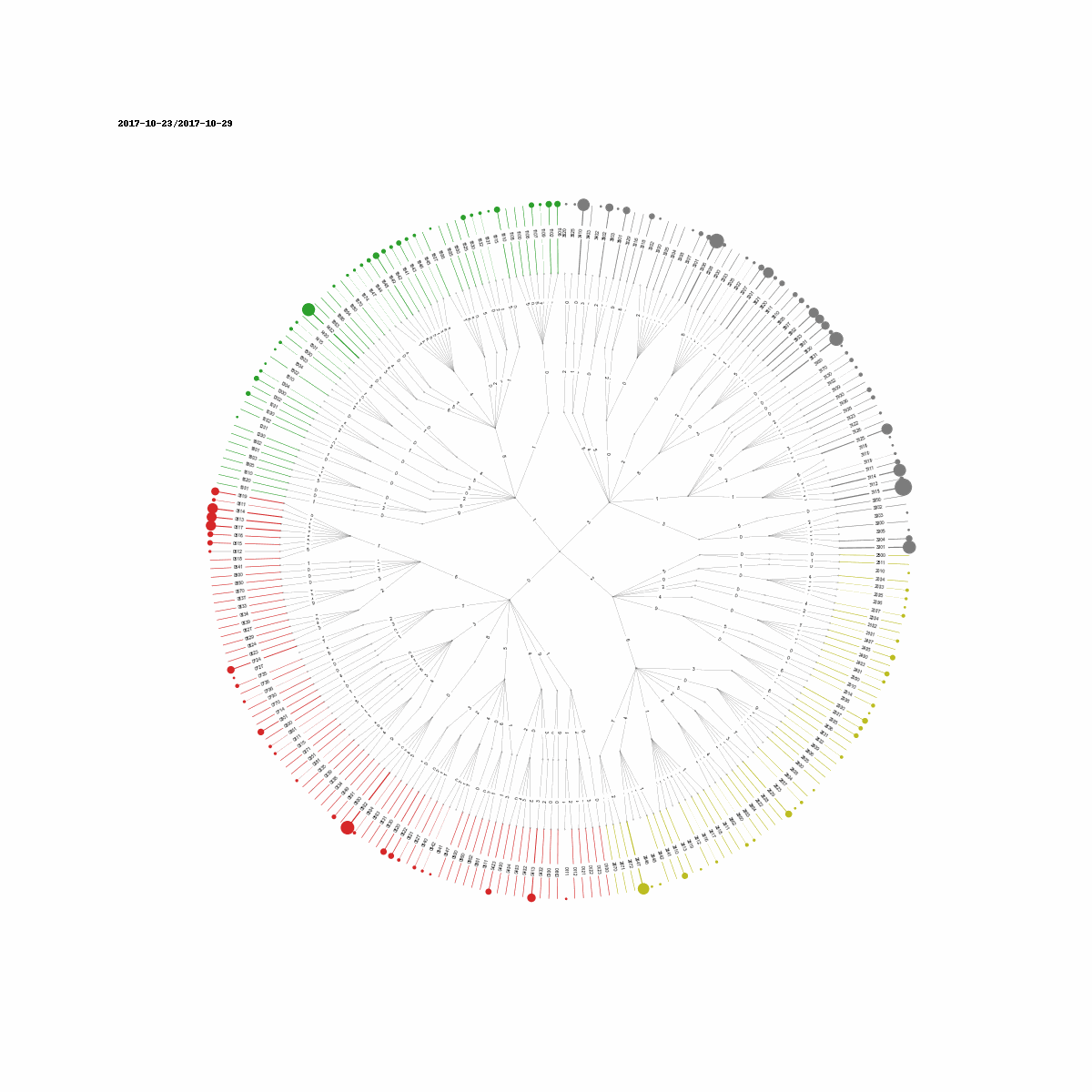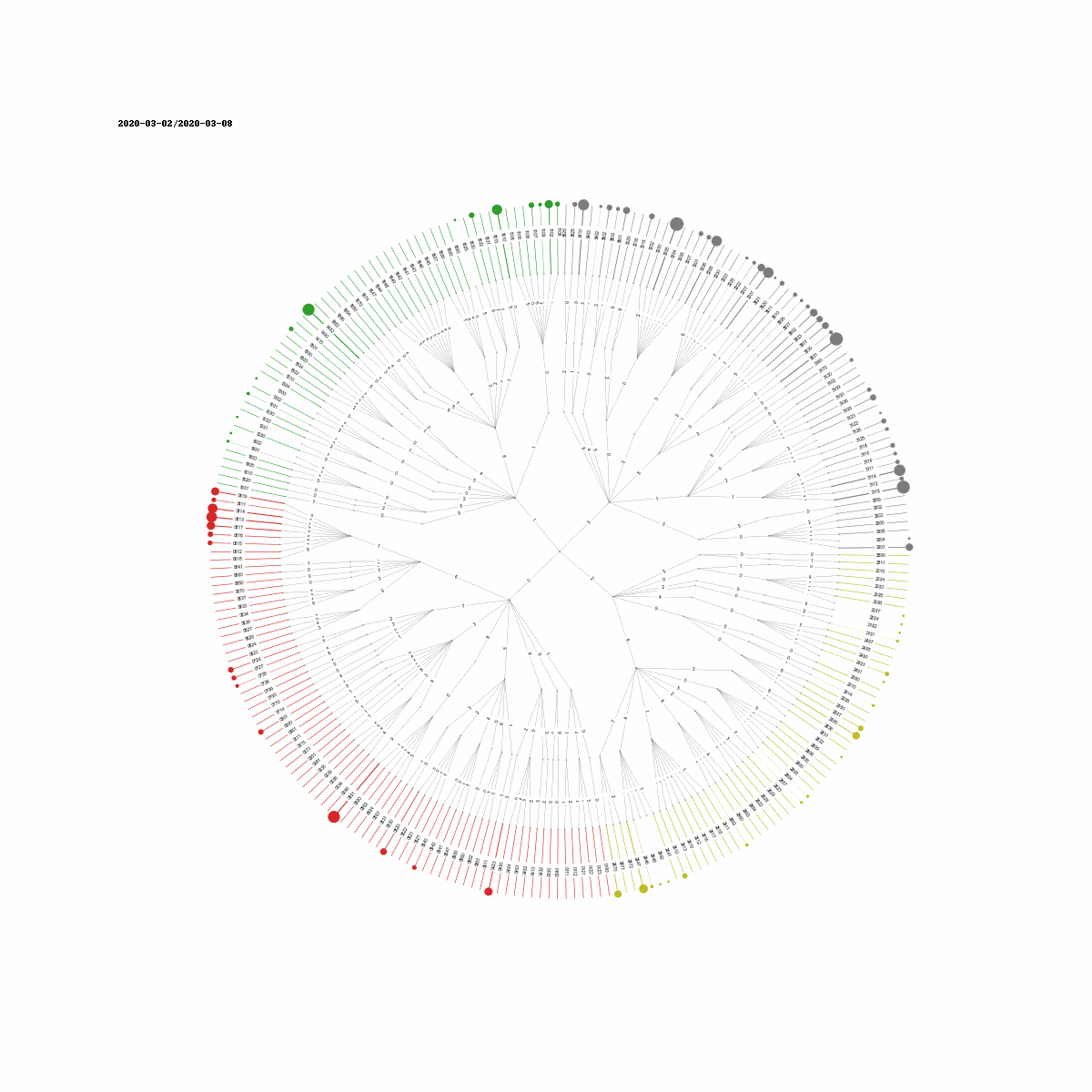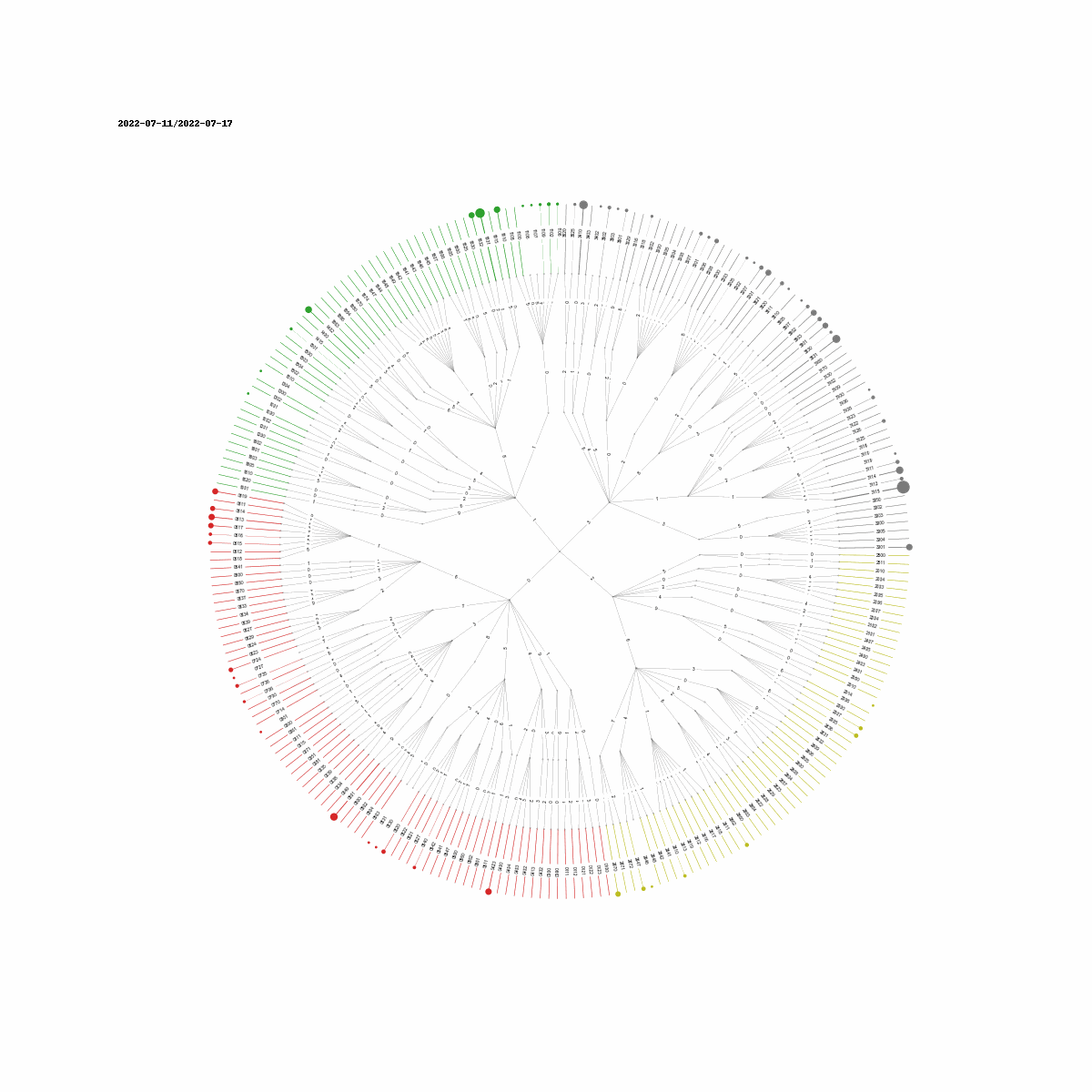
Grouping Incidents II (Time Series Clustering)
Anohter way to group this data is to first convert the incident counts to a min-max normalized (0-1) time series and clustering the different codes together based on Time Series CLustering methods. Two methods are descibed in this Kaggle notebook. We will be using K-means clustering from the package tslearn for this task.
We first convert the i_s index list to a datetime object list. This will help us plot the time series with appropriate x-axis labels.
yx = [datetime.datetime.fromtimestamp(int(i.to_timestamp().timestamp())) for i in i_s]
We now build a list of lists of each incident code. These lists are time series
count_series = {}
for v in gg.nodes:
if type(v) == int:
code = str(v).zfill(4)
count_series[v] = df[code].to_list()
count_normalized_series = {}
for k,v in count_series.items():
vals = np.array(v)
# count_normalized_series[k] = (vals - np.mean(vals))/np.std(vals)
_min = np.min(vals)
_max = np.max(vals)
count_normalized_series[k] = (vals-_min)/(_max-_min)
data_index = list(count_normalized_series.keys())
data = np.array(list(count_normalized_series.values()))
Next we will try using TimeSeriesKMeans to cluster the time series.
cluster_count = math.ceil(math.sqrt(len(data))) # number of clusters
km = TimeSeriesKMeans(n_clusters=cluster_count, metric="euclidean")
labels = km.fit_predict(data)
plot_count = math.ceil(math.sqrt(cluster_count))
fig, axs = plt.subplots(plot_count,plot_count,figsize=(25,25))
fig.suptitle('Clusters - Averaged',fontsize=60)
row_i=0
column_j=0
# For each label there is,
# plots every series with that label
for label in set(labels):
cluster = []
for i in range(len(labels)):
if(labels[i]==label):
axs[row_i, column_j].plot(yx,data[i],c="gray",alpha=0.4)
cluster.append(data[i])
if len(cluster) > 0:
axs[row_i, column_j].plot(yx,np.average(np.vstack(cluster),axis=0),c="red")
axs[row_i, column_j].set_title("Cluster "+str(label))
locator = mdates.AutoDateLocator()
formatter = mdates.ConciseDateFormatter(locator)
axs[row_i, column_j].xaxis.set_major_locator(locator)
axs[row_i, column_j].xaxis.set_major_formatter(formatter)
column_j+=1
if column_j%plot_count == 0:
row_i+=1
column_j=0
plt.show()

Here the red line is the average time series for the cluster.
How many incidents do we have per cluster?
pdata = []
for label in set(labels):
cluster = []
for i in range(len(labels)):
if(labels[i]==label):
cluster.append(data[i])
pdata.append((label,len(cluster)))
print("Cluster : " + str(label) + " : " + str(len(cluster)))
# plot pdata
fig, ax = plt.subplots(figsize=(10,5))
ax.bar([str(x[0]) for x in pdata],[x[1] for x in pdata])
ax.set_title("Number of Incidents in Each Cluster")
ax.set_xlabel("Cluster")
ax.set_ylabel("Number of Incident Types")
plt.show()

label_map = {}
for i in range(len(labels)):
label_map[data_index[i]] = labels[i]
Let's take a look at some of the clusters.
Cluster 1 is the largest cluster with 98 incidents. For cluster 1 incidents we have rare types with intermittent peaks.
cluster_number = 1
display(Markdown(f"### Codes for Cluster {cluster_number}"))
for k,v in label_map.items():
if v == cluster_number:
code = str(k).zfill(4)
description = combined_typed[combined_typed["OFFENSE_CODE"] == code]["OFFENSE_DESCRIPTION"].values[0]
print(f"{k} : {description}")
Cluster 8 has events that have dramatically increased since the end of 2019. Coinciding with the onset of the pandemic.
cluster_number = 8
display(Markdown(f"### Codes for Cluster {cluster_number}"))
for k,v in label_map.items():
if v == cluster_number:
code = str(k).zfill(4)
description = combined_typed[combined_typed["OFFENSE_CODE"] == code]["OFFENSE_DESCRIPTION"].values[0]
print(f"{k} : {description}")
Clusters 12,0,13 and 10 have events that have decreased since the end of 2019. Coinciding with the onset of the pandemic.
cluster_number = 0
display(Markdown(f"### Codes for Cluster {cluster_number}"))
for k,v in label_map.items():
if v == cluster_number:
code = str(k).zfill(4)
description = combined_typed[combined_typed["OFFENSE_CODE"] == code]["OFFENSE_DESCRIPTION"].values[0]
print(f"{k} : {description}")
cluster_number = 12
display(Markdown(f"### Codes for Cluster {cluster_number}"))
for k,v in label_map.items():
if v == cluster_number:
code = str(k).zfill(4)
description = combined_typed[combined_typed["OFFENSE_CODE"] == code]["OFFENSE_DESCRIPTION"].values[0]
print(f"{k} : {description}")
cluster_number = 13
display(Markdown(f"### Codes for Cluster {cluster_number}"))
for k,v in label_map.items():
if v == cluster_number:
code = str(k).zfill(4)
description = combined_typed[combined_typed["OFFENSE_CODE"] == code]["OFFENSE_DESCRIPTION"].values[0]
print(f"{k} : {description}")
cluster_number = 10
display(Markdown(f"### Codes for Cluster {cluster_number}"))
for k,v in label_map.items():
if v == cluster_number:
code = str(k).zfill(4)
description = combined_typed[combined_typed["OFFENSE_CODE"] == code]["OFFENSE_DESCRIPTION"].values[0]
print(f"{k} : {description}")
Cluster 11 has events that have stayed relatively periodic since 2015.
cluster_number = 11
display(Markdown(f"### Codes for Cluster {cluster_number}"))
for k,v in label_map.items():
if v == cluster_number:
code = str(k).zfill(4)
description = combined_typed[combined_typed["OFFENSE_CODE"] == code]["OFFENSE_DESCRIPTION"].values[0]
print(f"{k} : {description}")
Not much has changed in Bicycle related incidents since 2015. We can also take a look at the plots of the incidents of a cluster separately to verify the clustering.
def plotCluster(data, labels, cluster_number):
descriptions = {}
for k,v in label_map.items():
if v == cluster_number:
code = str(k).zfill(4)
description = combined_typed[combined_typed["OFFENSE_CODE"] == code]["OFFENSE_DESCRIPTION"].values[0]
descriptions[k] = description
cols = 3
rows = math.ceil(len(descriptions)/cols)
fig, axs = plt.subplots(rows,cols,figsize=(20,8))
fig.suptitle('Cluster ' + str(cluster_number),fontsize=16)
row_i=0
column_j=0
# For each label there is,
# plots every series with that label
for k,v in descriptions.items():
axs[row_i, column_j].plot(yx,data[data_index.index(k)],c="gray",alpha=0.4)
axs[row_i, column_j].set_title(f"{v}")
locator = mdates.AutoDateLocator()
formatter = mdates.ConciseDateFormatter(locator)
axs[row_i, column_j].xaxis.set_major_locator(locator)
axs[row_i, column_j].xaxis.set_major_formatter(formatter)
column_j+=1
if column_j%cols == 0:
row_i+=1
column_j=0
plt.show()
plotCluster(data, labels, 11)

As a sanity check we can also view the raw data without normalization to check if the results are similar.
data_raw = np.array(list(count_series.values()))
plotCluster(data_raw, labels, 11)

Thinking about the Data
I set out with the goal of using data visualization and analysis to convince a friend about th esafety of a certain area. However, to compare the data to the actual experience of living in an area is akin to spurious correlation. The data for example depends on a variety of factors. If staff was able to file the reports, funds allocated to different programs at the BPD, unemployment in an area, schools in an area. The data is influenced by a multitude of confounding factors. Property rates are often in a feedback loop with reports of crime. Where one influences the other. This curse of inferring causality from correlation is a common problem in data science. However we shall not be making that mistake here today. An exploration of the data is not enough to convince a friend but it is a stepping stone towards using data to ask questions of governance. For example, asking about the allocation of funds to different programs or asking the state to explain the reason for changes in the data.